Belangrijke opdracht

Re: Belangrijke opdracht
Wanneer ik het nareken met jouw waarden merk ik dat jij niet meer met de tijd hebt vermenigvuldigd in de Y matrix. Heeft dit een bepaalde reden? Want dan bekom je toch waarden in liter/u terwijl mijn bedoeling is om percentages te bekomen?

Re: Belangrijke opdracht
Met deze methode bepaal je voor je waarnemingen het best passende model
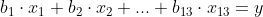
Dit werkt met getallen zonder eenheid of ongeacht de eenheid.
Tot zover de statistiek.
Nu de eenheden (ofwel de betekenis van je getallen):
Als de waarden een bepaalde eenheid hebben, moet je er wel voor zorgen dat de eenheden links en rechts gelijk zijn.
Als je b uitdrukt in liter/minuut en x in minuten, dan is de eenheid het product = liter.
= liter.
In dat geval moet y ook worden uitgedrukt in liters.
Volgens mij was je y gegeven in volume-eenheden, en niet in volume/tijd eenheid, daarom had ik in mijn eerdere post volume-eenheden gebruikt.
Als je je vergelijkingen in deze vorm wilt:
)
waarbij z in liters/minuut en alle x-en in minuten werkt de statistiek ook.
In dit geval is
)
en dus bepaal je z voor elk van je i waarnemingen via:
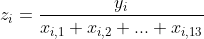
(NB: kijk in jouw berekening nog even goed na of het klopt wat je gedaan hebt:
z=y/x of z=y*x, volgens mij het laatste, was dat de bedoeling?)
Als je dit model gebruikt zoek je in feite het best passende lineaire model bij de relatieve tijdswaarden: je kan de formule
immers herschrijven naar

of in het kort:
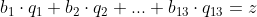
waarbij alle b's en z in liter/minuut en q dimensieloos.
Bovendien is q genormaliseerd:

Ook hierop kan je de regressie-analyse loslaten, het is aan jou om te kiezen voor de vorm die het best aansluit bij het onderwerp van je onderzoek.
Dit werkt met getallen zonder eenheid of ongeacht de eenheid.
Tot zover de statistiek.
Nu de eenheden (ofwel de betekenis van je getallen):
Als de waarden een bepaalde eenheid hebben, moet je er wel voor zorgen dat de eenheden links en rechts gelijk zijn.
Als je b uitdrukt in liter/minuut en x in minuten, dan is de eenheid het product
In dat geval moet y ook worden uitgedrukt in liters.
Volgens mij was je y gegeven in volume-eenheden, en niet in volume/tijd eenheid, daarom had ik in mijn eerdere post volume-eenheden gebruikt.
Als je je vergelijkingen in deze vorm wilt:
waarbij z in liters/minuut en alle x-en in minuten werkt de statistiek ook.
In dit geval is
en dus bepaal je z voor elk van je i waarnemingen via:
(NB: kijk in jouw berekening nog even goed na of het klopt wat je gedaan hebt:
z=y/x of z=y*x, volgens mij het laatste, was dat de bedoeling?)
Als je dit model gebruikt zoek je in feite het best passende lineaire model bij de relatieve tijdswaarden: je kan de formule
immers herschrijven naar
of in het kort:
waarbij alle b's en z in liter/minuut en q dimensieloos.
Bovendien is q genormaliseerd:
Ook hierop kan je de regressie-analyse loslaten, het is aan jou om te kiezen voor de vorm die het best aansluit bij het onderwerp van je onderzoek.
Re: Belangrijke opdracht
Dit zal inderdaad beter zijn, maar het principe blijft toch hetzelfde denk ik? Aangezien beide zijden van de vergelijking gedeeld worden door de totale tijd. Ik wacht nog steeds op meer waarden en hoop dat het probleem daarmee opgelost is.
Re: Belangrijke opdracht
Ik heb ondertussen nieuwe waarden ontvangen. Ik heb nu 6 onbekenden en 10 vergelijkingen maar bekom nog steeds negatieve waarden. Ik doe nu de lineaire regressie met het programma StatPlus (wat goed werkt). Ik zie geen andere oplossing meer dan degene die nu op tafel ligt.. Dus ik vrees dat ik niet in mijn opzet zal slagen
Re: Belangrijke opdracht
Zelf met meerdere waarden blijft het probleem hetzelfde..
Re: Belangrijke opdracht
Vreemd, dan heb ik nog een aantal vragen:
Hoeveel onbekenden en hoeveel vergelijkingen heb je nu precies?
Is het mogelijk dat er 1 of meerdere foutieve metingen zijn?
Of notatiefouten (bv 2 cijfers verwisseld, cijfer vergeten, verkeerde getal opgeschreven, een meetwaarde aan de verkeerde variabele toegekend, etc)?
Als het om 1 of enkele incidentele (geisoleerde) fouten gaat zijn deze vaak rekenkundig op te sporen.
Voorbeeld:
Een eenvoudige manier om 1 foutieve vergelijking (uit de n vergelijkingen die je hebt) op te sporen is:
- laat uit al je n vergelijkingen de eerste vergelijking weg,
- kijk wat je model wordt met de overgebleven (n-1) vergelijkingen
- en hoe goed dit model de waarde van de weggelaten vergelijking voorspelt.
Herhaal dit proces door achtereenvolgens
- uit je n vergelijkingen de 2e vergelijking weg te laten,
- uit je n vergelijkingen de 3e vergelijking weg te laten,
etc.
Als het gaat om 1 zeer afwijkende vergelijking (een outlier of uitschieter), kan je die vergelijking op deze manier vaak identificeren:
- ten eerste zal het model beter voldoen aan wat je verwacht, en
- ten tweede wijkt de waarde die het model voor deze vergelijking voorspelt vaak sterk af van de gemeten waarde voor deze vergelijking.
Als je n vergelijkingen hebt moet je dus n van deze berekeningen maken, wel een klus.
Bij voorkeur zou je dat willen automatiseren, zeker als je ook combinaties van 2 of meer vergelijkingen zou willen uitsluiten. Als dat je te ver gaat mag je me je dataset X en Y nog een keer toesturen zodat ik er nog eens naar kan kijken.
Hoeveel onbekenden en hoeveel vergelijkingen heb je nu precies?
Is het mogelijk dat er 1 of meerdere foutieve metingen zijn?
Of notatiefouten (bv 2 cijfers verwisseld, cijfer vergeten, verkeerde getal opgeschreven, een meetwaarde aan de verkeerde variabele toegekend, etc)?
Als het om 1 of enkele incidentele (geisoleerde) fouten gaat zijn deze vaak rekenkundig op te sporen.
Voorbeeld:
Een eenvoudige manier om 1 foutieve vergelijking (uit de n vergelijkingen die je hebt) op te sporen is:
- laat uit al je n vergelijkingen de eerste vergelijking weg,
- kijk wat je model wordt met de overgebleven (n-1) vergelijkingen
- en hoe goed dit model de waarde van de weggelaten vergelijking voorspelt.
Herhaal dit proces door achtereenvolgens
- uit je n vergelijkingen de 2e vergelijking weg te laten,
- uit je n vergelijkingen de 3e vergelijking weg te laten,
etc.
Als het gaat om 1 zeer afwijkende vergelijking (een outlier of uitschieter), kan je die vergelijking op deze manier vaak identificeren:
- ten eerste zal het model beter voldoen aan wat je verwacht, en
- ten tweede wijkt de waarde die het model voor deze vergelijking voorspelt vaak sterk af van de gemeten waarde voor deze vergelijking.
Als je n vergelijkingen hebt moet je dus n van deze berekeningen maken, wel een klus.
Bij voorkeur zou je dat willen automatiseren, zeker als je ook combinaties van 2 of meer vergelijkingen zou willen uitsluiten. Als dat je te ver gaat mag je me je dataset X en Y nog een keer toesturen zodat ik er nog eens naar kan kijken.